 H深夜笔记
H深夜笔记前面我发了使用php解析下载抖音无水印视频的教程,今天我来教大家如何用python 爬取下载抖音的无水印视频
话不多说 开始!因为在前面文章中有关于寻找抖音的json接口,这边我就不再提了,有兴趣的可以去翻翻看我发的解析抖音视频php篇教程。我们前面的跳过,直接开始代码部分!
步骤一:首先请求302重定向的地址
如我们复制的抖音视频分享链接都是下面这样的
4.15 usE:/ 化妆简直邪术 https://v.douyin.com/8NTarjq/ 复zhi佌链接,答汧Dou音搜索,直接观kan视频!
我们需要用request请求这段文本中的链接 https://v.douyin.com/8NTarjq/
html = requests.get(t[0], allow_redirects=False)
url2=html.headers['Location']# 获取跳转地址因为链接会进行302重定向跳转,所以需要在请求的时候加个allow_redirects=False参数,它的返回值是这样的
https://www.iesdouyin.com/share/video/6997004782640598310/?region=CN&mid=后面还有一堆参数,
这条链接是该视频的网页地址,我们需要的就是video/()/?region中间的这串数6997004782640598310将这串数字拼接在抖音官方的json接口上,如下就是拼接好的视频json数据链接,大家可以访问看看
https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids=6997004782640598310
步骤二:请求json链接
上面我们获取拼接了视频的json链接,大家写代码的时候可以把链接复制到浏览器打开查看具体内容
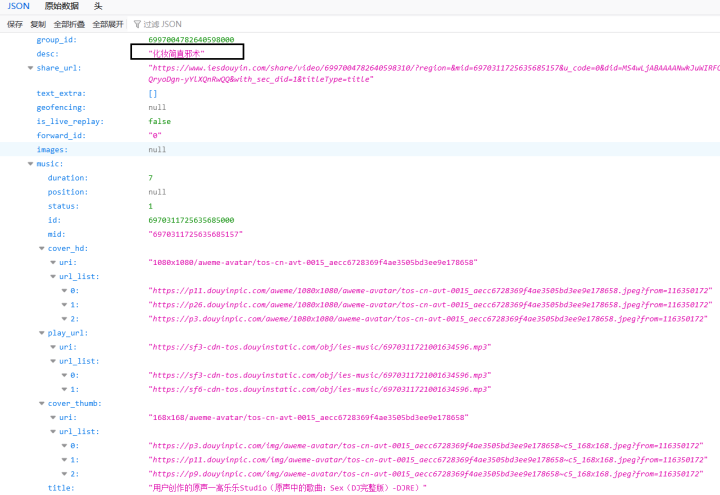
我们还是用request请求链接,通过浏览器看json内容,获取我们需要的相关值
html2 = requests.get(ur,headers=headers) #请求json链接
title=html2.json()['item_list'][0]['desc'] #抖音视频的文案内容
video_id=html2.json()['item_list'][0]['video']['play_addr']['uri'] #视频的uri,也就是video_id
video_url=f'https://aweme.snssdk.com/aweme/v1/play/?video_id={video_id}&ratio=720p&line=0'步骤三:对链接进行拼接
因为所有视频的地址只有video_id不一样,所以我们主要的就是获取json返回数据中的video_id,然后和https://aweme.snssdk.com/aweme/v1/play/?video_id= 拼接在一起,就是抖音无水印视频的地址了,当我们访问的时候,它还会重定向跳转到视频的真实地址,我们访问这段链接就能下载到无水印视频。
下面这个就是我们拼接好的无水印视频
https://aweme.snssdk.com/aweme/v1/play/?video_id=v0d00fg10000c4d5klrc77u1kmdccc6g

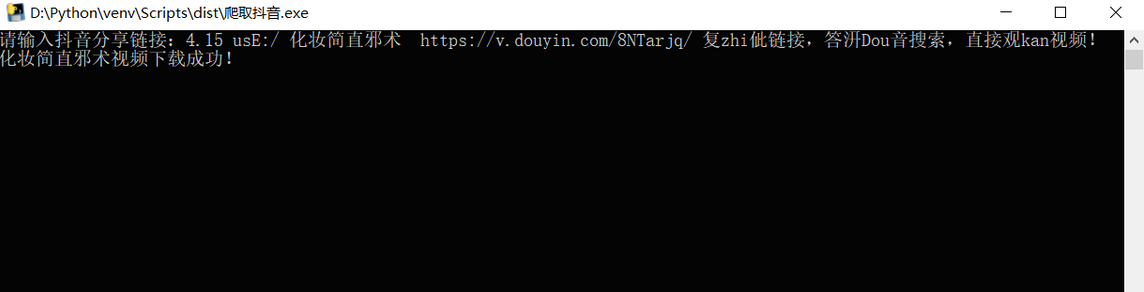
完整源代码附上:
import requests # 导入requests模块
import re
import os
def dy(txt):
t = re.findall('(https://v.douyin.com/.*?/)', txt, re.S)
if len(t)!=0:
html = requests.get(t[0], allow_redirects=False)
# 获取跳转地址
url2=html.headers['Location']
#print(url2)
item_ids = re.findall('video\/(.*?)\/\?region', url2)
if len(item_ids)!=0:
ur=f'https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids={item_ids[0]}'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3877.400 QQBrowser/10.8.4506.400',
'cookie': '__gads=ID=0613c5de4392f6a6-2268f52184cf0004:T=1640239783:RT=1640239783:S=ALNI_MYFmzURQ4PZLUsx8kWq5VTByZe82A; Hm_lvt_338f36c03fc36a54e79fbd2ebdae9589=1640239784,1640259798; Hm_lpvt_338f36c03fc36a54e79fbd2ebdae9589=1640259798'
}
html2 = requests.get(ur,headers=headers)
# print(html2) # 链接成功200
t2=html2.json()
title=html2.json()['item_list'][0]['desc']
# print(title)
video_id=html2.json()['item_list'][0]['video']['play_addr']['uri']
video_url=f'https://aweme.snssdk.com/aweme/v1/play/?video_id={video_id}&ratio=720p&line=0'
html3=requests.get(video_url,headers=headers)
#print(html3.url)
video_response = requests.get(url=video_url, headers=headers) # 发送下载视频的网络请求
if video_response.status_code == 200: # 如果请求成功
z = os.getcwd()
temp_path = z + '/抖音视频/' # 在程序当前文件夹下建立文件夹
if not os.path.exists(temp_path):
os.makedirs(temp_path)
data = video_response.content # 获取返回的视频二进制数据
rstr = r"[\/\\\:\*\?\"\<\>\|]" # '/ \ : * ? " < > |'
new_title = re.sub(rstr, "_", title) # 过滤不能作为文件名的字符,替换为下划线
c = '%s.mp4' % new_title # 视频文件的命名
file = open(temp_path + c, 'wb') # 创建open对象
file.write(data) # 写入数据
file.close() # 关闭
print(title+"视频下载成功!")
else:print('请输入正确的分享链接!')
while 1:
txt = input("请输入抖音分享链接(0退出):")
if txt!=str(0):
dy(txt)
else:
print("退出")
break
附上我做好的抖音无水印视频解析接口供大家使用,接口地址:https://hmily.vip/api/dy/?url=
使用方法:在接口地址后面加上你要下载的抖音视频链接就行了,返回的是json数据
.
有帮助的话,欢迎分享给更多的人,仅供大家学习交流!


html2 = requests.get(ur,headers=headers)
现在这个函数返回为空了,是不是API又改了?